集成学习
概念
组合多个弱监督模型以期得到一个更好更全面的强监督模型。潜在思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
特点:将多个分类方法聚集在一起,以提高分类的准确率;
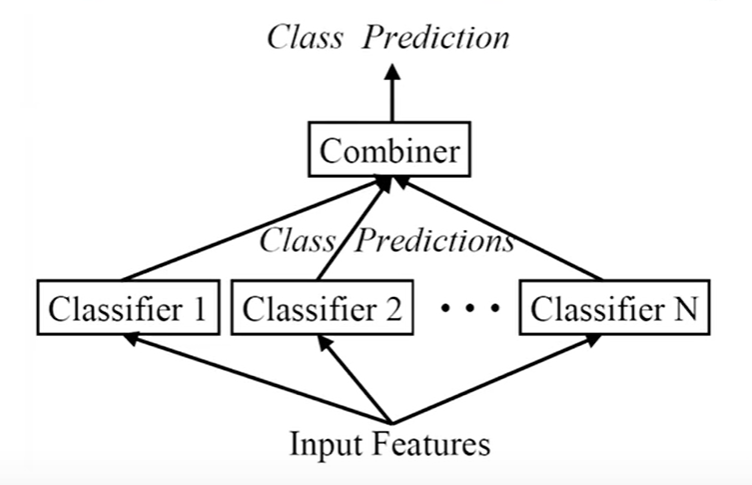
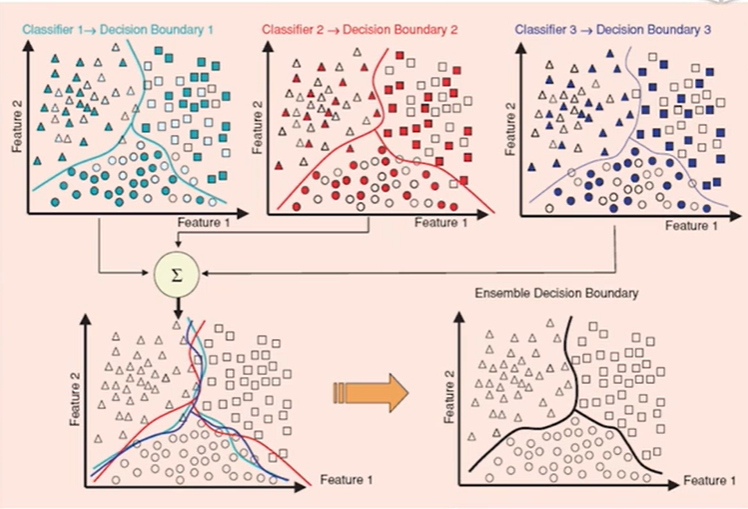
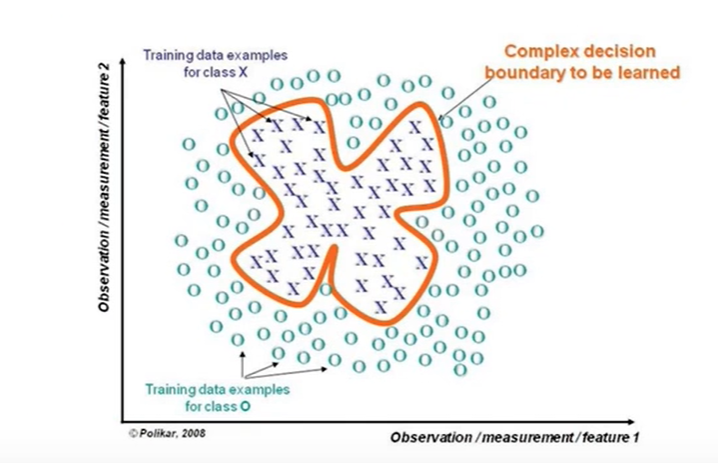
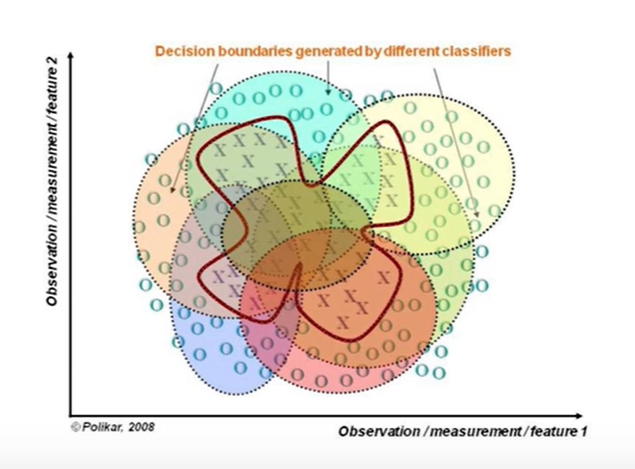
集成学习的关键:
- 可以纠正其它分类器的错误;
- 如果所有模型都相同,则不会产生作用 。
(一般选择同样的分类器,不同的决策树【训练集】)
怎么选择不同的训练样本?有放回的采样,即bootstrap。
Bagging(Bootstrap Aggregating)
投票决策,少数服从多数。“随机森林Random Forests”
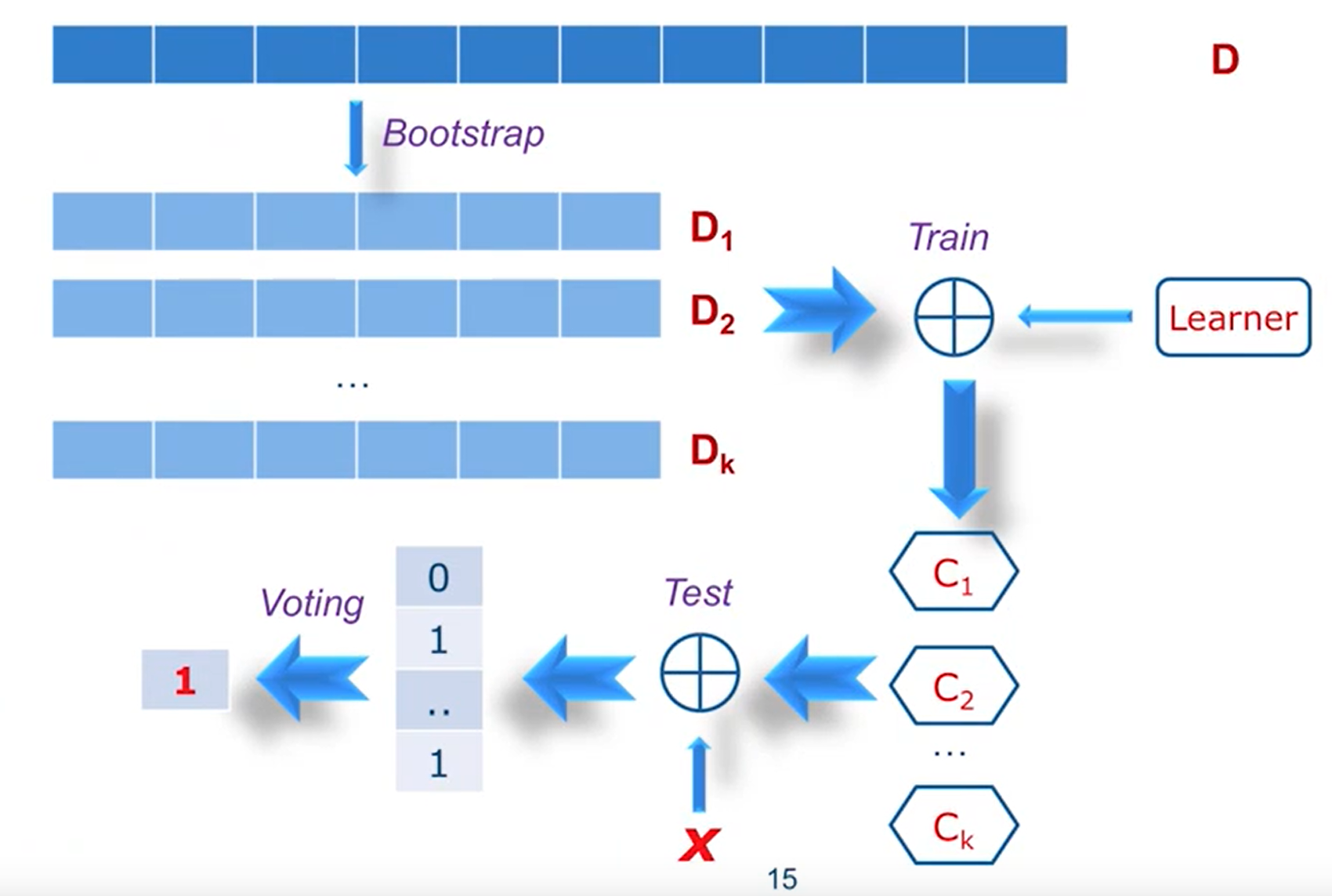

stacking:在bagging基础上增加分类器的权重。
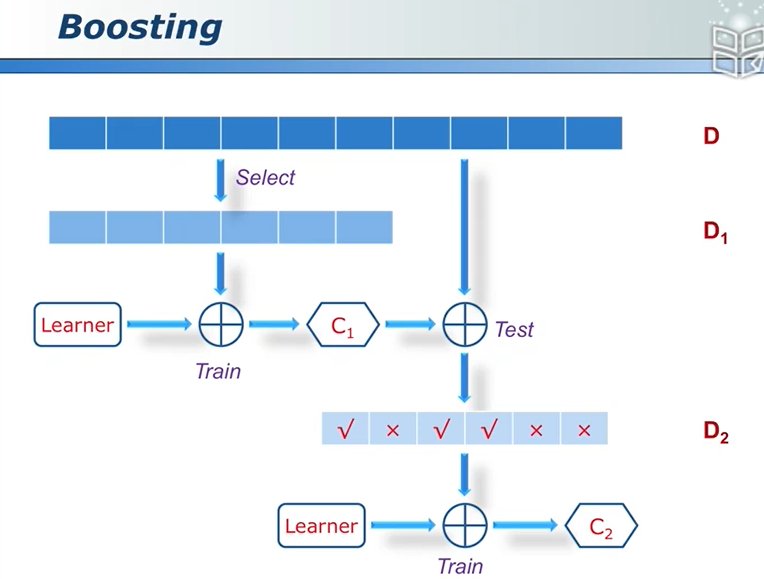
Boosting
分类器串联,通过提高那些在前一轮被弱分类器分错样例的权值,来使得分类器对误分的数据有较好的效果,
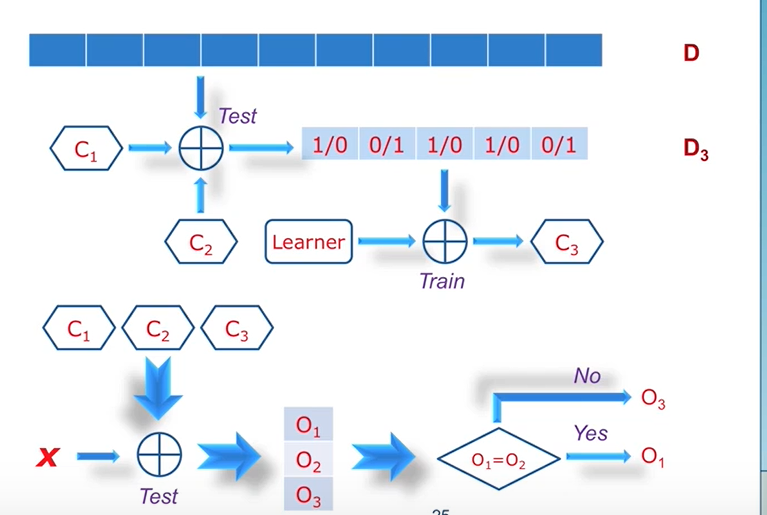

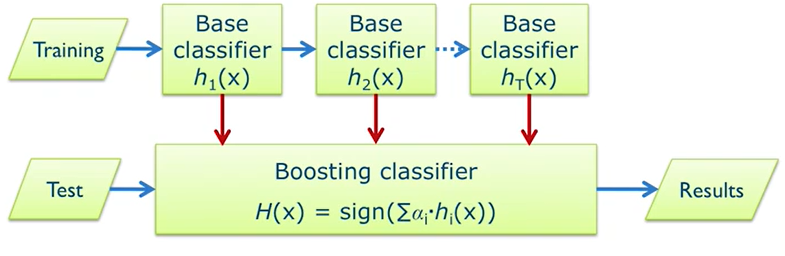
AdaBoost
刚开始训练时对每一个训练集赋以相同的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练集赋以较大的权重,从而得到多个预测函数,通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
误差是逐渐趋近于0。

Bagging与Boosting区别
1、样本选择上
Bagging:训练集是在原始集中有放回的选取,从原始集中选出的各轮训练集之间是独立的;
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化,权值是根据上一轮的分类结果进行调整。
2、样例权重
Bagging:使用均匀取样,每个样例的权重相等;
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3、预测函数
Bagging:所有预测函数的权重相等;
Boosting:根据错误率不断调整样例的权值,错误率越大权重越大。
4、并行计算
Bagging:各个预测函数可以并行生成;
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。



