基于电极选择和卷积注意网络的EEG信号识别
Abstract
①、电极选择方法为想象语言识别提供了包含最具辨别力的时频信息的电极;
②、来自选定电极的频谱图被用作卷积注意网络的输入,卷积注意网络提取时频特征,并为具有更高辨别能力的时间点赋予更高的重要性来执行分类。
关键词:EEG,脑机接口,卷积网络,注意力,电极选择,时频
Introduction
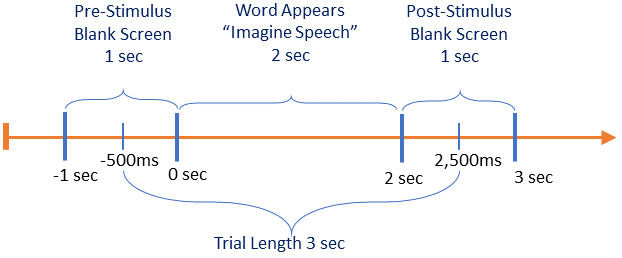
数据采集流程
1、首先,一个空白屏幕出现了1秒,参与者没有进行任何活动。
2、随后,单词出现2秒钟,参与者被告知在出现单词后立即在脑海中阅读。
3、单词演示之后是另一个空白屏幕,持续1秒。每次试验持续4秒;
然而,只有3秒(刺激开始前500毫秒和刺激开始后2500毫秒)的试验用于避免试验之间的EEG活动重叠。每个参与者对每个单词进行十次测试。数据记录是时间锁定的,以确保刺激在正确的时间出现在屏幕上。为了尽量减少疲劳,参与者在实验进行到一半时得到了休息。
预处理
从EEG信号中去除噪声和伪影,如眨眼、眼球运动、呼吸和肌肉运动。
滤波:0.01Hz高通滤波;利用陷波滤波器去除50Hz噪声;利用肌电电极消去在高频处的噪声,如肌肉运动造成的噪声;进行基线校正。
使用时频信息进行电极选择
1、短时傅里叶变换
在本研究中使用短时傅立叶变换(STFT)来分析大脑信号。
STFT计算过程中使用了开窗,以避免被称为泄漏的不连续性。我们在STFT实现中使用了Hann窗口。 窗口的长度为256,时间重叠为87%在连续的窗口之间使用。
短窗口提供了极好的时间分辨率,有助于检测信号中的事件。
此外,我们还进行了基线归一化,以避免在高频下降低功率表示。基线标准化也有助于突出任务区分活动与背景活动。
2、使用频谱图进行电极选择
提出了一种电极选择方法,为想象语音的识别提供了最具任务分辨力的电极。

所提出的方法从所有电极获取输入频谱图,并选择最有助于识别无声语音单词的$K$个电极。其中$K$是一个用户定义的参数。电极选择算法的输入是训练数据$X∈R^{n×C×T×F}$,其中$n$代表训练试验的总次数,$T$代表了频谱图中总的时间点数,$F$代表频谱图中频率点的总数,$C$是电极的总数。
第一步是在时间轴上计算频谱$S_{t,f}$的平均值。这是在所有试验和电极的频谱上进行的。它为每个电极在每次试验上生成了一个频率向量$S_f$,来自每个电极的$S_f$被划分为不同长度的$j$个重叠向量。从向量$S_f$中获得第$j$个重叠向量$S_{f’_j}$,其中$f− m_j$指新向量$S_{f’_j}$的长度。
在具体分析中,我们创建了三个新的向量$(j=3);S_{f’_1},S_{f’_2},S_{f’_3}$. 所有向量的长度都不同,比如$S_{f’_1}$的长度小于$S_{f’_2}$,$S_{f’_3}$的长度最大。估计每个向量$S_{f’_j}$的平均值,其中$a_j$是第$j$个向量的平均值。这样做是为了从不同的频段捕捉活动的幅度。如果向量$S_{f′_j}$的平均$a_j$大于零,则该方法将电极视为信息电极。计算平均值以提供向量$S_{f′_j}$内总功率的测量值。得到了一个大小为$n×C$的矩阵$X_f$,其中包含了所有$n$次试验中关于$C$电极的信息。矩阵的第$C$位包含$1$或$0$值,这取决于向量的平均值$a_j$(算法$1$,步骤$8$)。$X_f(n,C)$中的所有值沿$n$轴相加,得到一个数组。从该阵列中,检索到具有最高值的$K$电极的指数。这些被认为是信息量最大的电极。$top-K$电极使用训练数据进行估计,测试数据中使用相同的电极进行分类。
使用卷积注意网络进行分类
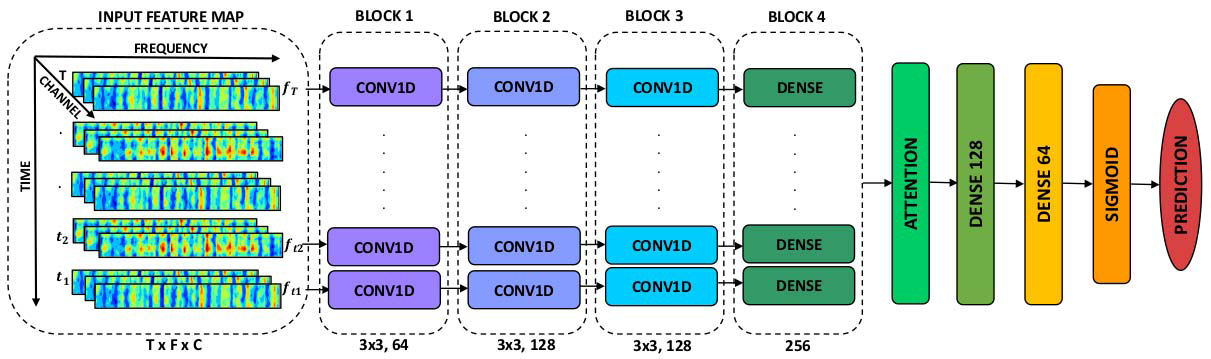
本次提出的网络架构图使用卷积层和注意层去从输入频谱图中学习频谱和时间模式。在第一阶段,网络使用卷积层从频谱图的每个时间点提取重要的频率成分。此外,池化层对卷积块提取的特征进行降维。我们使用自我注意机制从卷积块提取的特征中学习重要的时间点。自我注意层强调提供最具辨别力特征的时间点。这使得网络能够学习属于所选电极频谱图的重要频谱时间成分。
因为与短时认知活动相关的神经事件只持续几毫秒。因此,并非所有的EEG时间点都有助于检测。因此,使用自我注意机制来突出卷积密集块产生的输出中信息量最大的时间方面。为了将注意力整合到我们的网络中,我们创建了一个自我注意层,该层使用平行密集层的输出作为输入,构建了一个信息更丰富的全局特征图g。为了实现自我注意机制,我们首先使用两个连续的全连接层计算归一化的重要性向量:第一层(FC1)带有tanh,第二层(FC2)带有SoftMax激活函数。两层都只有一个神经元。自我注意层使用反向传播进行训练,梯度用于学习重要的时间点。
神经网络中的自我注意力机制
注意力机制的基本思想就是让模型能够忽略无关信息而更多的关注我们希望它关注的重点信息。近几年深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。(本质是希望通过学习得到一组作用在原图上的权重分布)。
注意力有两个大的分类:软注意力和硬注意力。软注意力的关键在于其是可微的,可以计算梯度,来利用神经网络的训练方法获得。这是我们关注的重点。
机制的运用大概可以分为两个方向:1. 增强特征聚合;2. 通道与空间注意相结合。常用的CNN-Attention有SEnet(Squeeze-and-Excitation Network)和CBAM(Convolutional Block Attention Module)等。
SEnet
Squeeze-and-Excitation Networks (arxiv.org)
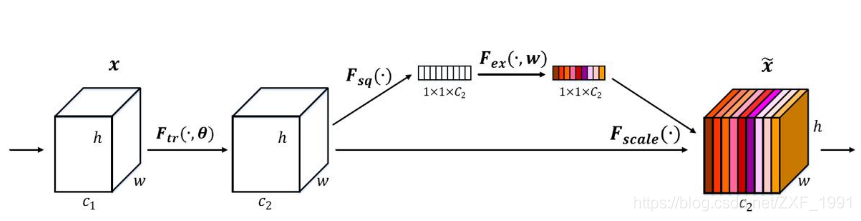
SEnet通过学习的方式自动获取每个特征通道的重要程度,目的是自动提升有用特征并抑制不重要的特征。SEnet通过Squeeze模块和Excitation模块实现所述功能。
squeeze操作:对空间维度进行压缩,直白的说就是对每个特征图做全局池化,平均成一个实数值。该实数从某种程度上来说具有全局感受野。
excitation操作:由于经过squeeze操作后,网络输出了1×1×C大小的特征图,作者利用权重w来学习C个通道直接的相关性。在实际应用时有的框架使用全连接,有的框架使用1×1的卷积实现。推荐使用1×1的卷积,先对通道进行降维然后在升维到C,好处就是一方面降低了网络计算量,一方面增加了网络的非线性能力。
最后一个操作时将excitation的输出看作是经过特征选择后的每个通道的重要性,通过乘法加权的方式将excitation的输出乘到先前的特征上,从事实现提升重要特征,抑制不重要特征这个功能。
CBAM
Squeeze-and-Excitation Networks (arxiv.org)
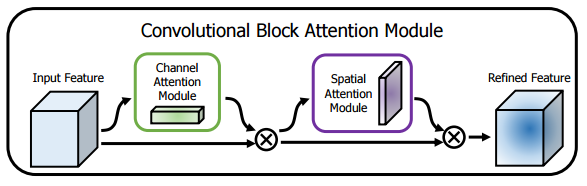
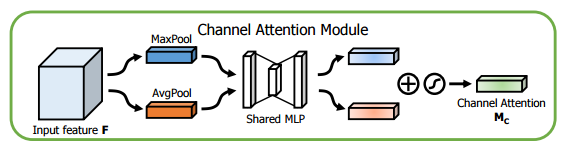
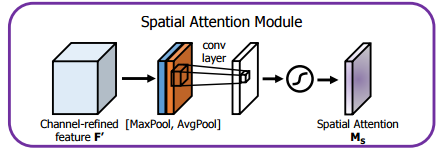
CBAM在特征通道和特征空间两个维度加入注意力机制。
特征通道中加入注意力机制,和SE思想类似,区别是加入了一个max pooling操作,而且共享了一个MLP(多层感知机)。具体操作为:将输入的特征图,分别经过基于宽度和高度的全局最大池化和全局平均池化,然后分别经过共享的MLP。将MLP输出的特征进行元素方面的加和操作,再经过sigmoid激活函数,生成最终的通道注意特征图。将这个通道注意特征图和输入特征图做元素方面的乘法操作,生成空间注意模块需要的输入特征。
特征空间中加入注意力机制,具体操作:将通道注意模块输出的特征图作为本模块的输入,首先对输入做一个基于通道的全局最大池化和全局平均池化,然后将这2个结果基于通道做拼接操作。然后经过一个卷积操作,降维为1个通道。再经过sigmoid生成空间注意特征。最后将该特征和该模块的输入特征做乘法,得到最终生成的特征。



